Continued from the previous post…
This one is very interesting. Classic LSM-tree based key-value stores batch I/Os to take advantage of HDDs sequential throughput. To enable efficient lookups, LSM-trees continuously read, sort, and write key-value pairs in the background, resulting IO amplification. LevelDB and RocksDB are two popular key-value stores built on top of LSM-trees.
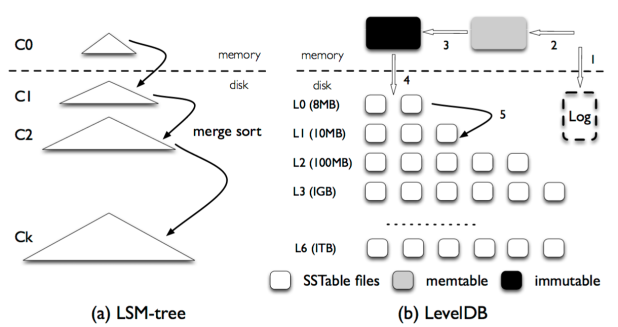
Directly applying them to SSDs is not a good idea, because
- The difference between random and sequential IOs’ performance is not as huge as HDDs.
- SSDs have a large degree of internal parallelism.
- SSDs can wear out through repeated writes.
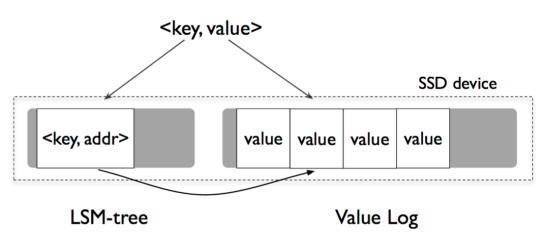
WiscKey’s central idea is to separate keys and values.
- Only keys are kept sorted in the LSM-tree, while values are stored separately in a log. As a result, key sorting and garbage collection are decoupled.
- As values are unsorted, parallel random-reads are used for range queries to exploit SSDs internal parallelism.
WiscKey has been shown up to 100x faster than LevelDB in microbenchmarks. It is also faster than both LevelDB and RocksDB in YCSB workloads.
Due to limited time (mostly my laziness), I’m not going to write in-depth analysis here. But, I think this paper deserves careful reading. I would refer interested readers to the original paper for many technical details and discussions.
Okay, dedup. Deduplication is important for storage systems built for large datasets, is well-studied, and yet is difficult. (When talking about dedup, Yale alumni Kai Li and his Data Domain Inc. always pop up in my mind :).)
How to deduplicate data is one aspect of the topic, but today we’re talking about another aspect — how to estimate the deduplication ratio before the actual dedup operation is carried out. This is useful because it helps one early at the planning phase. A misplanned hardware/software platform might requires much more cost to increase the capacity or leave much more unused resource to be wasted. Therefore, a good estimation of the dedup ratio is a very important piece in the initial system design.
Continue reading →